AI CRO
The State of CRO in 2026: 5 Findings from GoGoChimp's Client Portfolio + Build Grow Scale's 347-Store Research
Last updated: [Updated Date]


If you're looking for a list of generic CRO tips, stop reading here. Honest answer from 13 years on the inside: the five findings below come from real client engagements, not vendor decks. Each is backed by Build Grow Scale's industry research across 347 stores. Each is uncomfortable enough that most CRO blogs won't print it. If you're spending over £10K/month on ads and converting under 2%, you're the reader this post is for.
Why "the state of CRO" needs honest data, not vendor-curated data
.png)
Most "state of CRO" reports are written by tool vendors with a product to sell. The numbers are real. The framing is selective. You read the report, you nod along, you walk away with a vague sense that AI is good and testing is important. Nothing changes on Monday.
This post is built differently. The academic anchor is Build Grow Scale's 2026 review of 347 e-commerce stores doing $300K to $8M per month. The proprietary layer is GoGoChimp's 13-year portfolio of named-client engagements plus 12 weeks of our own AI-citation tracking that nobody else has. The Build Grow Scale numbers tell you what's true across the industry. Our own data tells you what's true once a CRO expert is in the loop.
Build Grow Scale's 2026 review of 347 e-commerce stores (Stafford, 2026) found expert-guided AI testing delivered average conversion lifts of 28-34%, compared to 4-7% from DIY AI tools. The AI isn't the differentiator. The CRO expert is.
The 28-34% figure is the headline. The five findings below are the mechanism. Then we go further than any other 2026 state-of-CRO piece you'll find: into the AI-citation surface where the next wave of CRO traffic is being won and lost.
What does "honest data" mean in 2026?
It means you can click through every number in this post to its primary source. It means no fabricated competitor pricing, no plagiarised client numbers, no rounded-up averages presented as research. It means I name the cases where my own tests lost money (Finding 4) and the engines where we're getting nowhere (Finding 6's tracker reveal). Vendor reports never do that. The rest of this post is built on the same standard.
The research foundation: Build Grow Scale's 2026 review of 347 stores
Build Grow Scale's recap is the most citable CRO dataset published this decade. Matthew Stafford and his team measured conversion rates and average order value across 347 stores running A/B tests through 2025. The split was clean: stores using DIY AI tools (auto-optimisation features, generative copy without an expert) returned 4-7% average lift. Stores using expert-guided AI (a CRO expert setting hypotheses, AI handling test execution and variant generation) returned 28-34%.
The difference is a multiple of five. The software is the same. The CRO expert is the variable.
The landing-page side of the same picture is Unbounce's Conversion Benchmark Report: a cross-industry median conversion rate of 6.6% across 41,000 landing pages, 464 million pageviews, and 57 million conversions. That dataset is the cleanest published anchor for what a typical landing page actually does. The 28-34% expert-led lift band, applied to a 6.6% baseline, lands at roughly 8.5% to 8.8%. Aggregator reports that claim 8-9% medians are the inflated number; 6.6% is the dataset-backed reality and the honest starting point for any lift conversation.
You won't like this, but you'll find the same pattern playing out in checkout. Baymard Institute's 2026 meta-analysis across 50 separate studies puts average cart abandonment at 70.19%, with mobile at 80.02% and desktop at 66.41%. The honest read: half the lift available in CRO this year sits in the gap between "visitor lands" and "visitor checks out". That gap is bigger than every clever button-colour test combined.
I cite Build Grow Scale on every client call. It's the canonical answer to "does AI CRO work?" My advice is that the honest answer is: it depends entirely on who's driving. Self-serve AI returns the bottom of the lift distribution. A CRO expert with 13 years of pattern-recognition lives at the top. Read the full thesis in our OperatorAI methodology and our breakdown of The 4-to-34 Gap.
How does this compare to the Authoritas + 5WPR data?
The 5WPR AI Platform Citation Source Index 2026 synthesised 680 million individual AI citations across ChatGPT, Google AI Overviews, Perplexity, Gemini, and Claude across an August 2024 to April 2026 window. Authoritas's parallel work measured AI Overview prevalence at 12.2% of news-keyword searches with a 47.5% desktop CTR drop on publisher pages where an AI Overview surfaced (via Press Gazette). Both datasets converge on the same point Build Grow Scale's 347-store work makes from a different angle: in 2026, owning the citation matters more than owning the click.
What our client portfolio adds: 5 findings from 13 years of named-client engagements
The 347-store dataset is breadth. The GoGoChimp portfolio is depth. Five clients, five distinct lessons. Each finding maps onto a pattern Build Grow Scale documented in aggregate, with named-client receipts that show the mechanism.

The clients named below have given public-naming permission. The numbers come from internal reporting documents and published case studies. Nothing's rounded up. Nothing's invented.
The five findings, in order:
- Page speed is the delivers layer that makes every other test possible.
- Counter-intuitive imagery beats convention more often than convention beats data.
- One specific headline change can outperform 30 minor tests.
- The lowest-confidence test often delivers the biggest upside.
- B2B conversion can move 50-fold or more when the pain-naming is precise.
Each gets its own section, its own client data, its own connection to Build Grow Scale's research, and its own practical synthesis.
Finding 1: Page speed is the delivers layer, not a "7% per second" line item
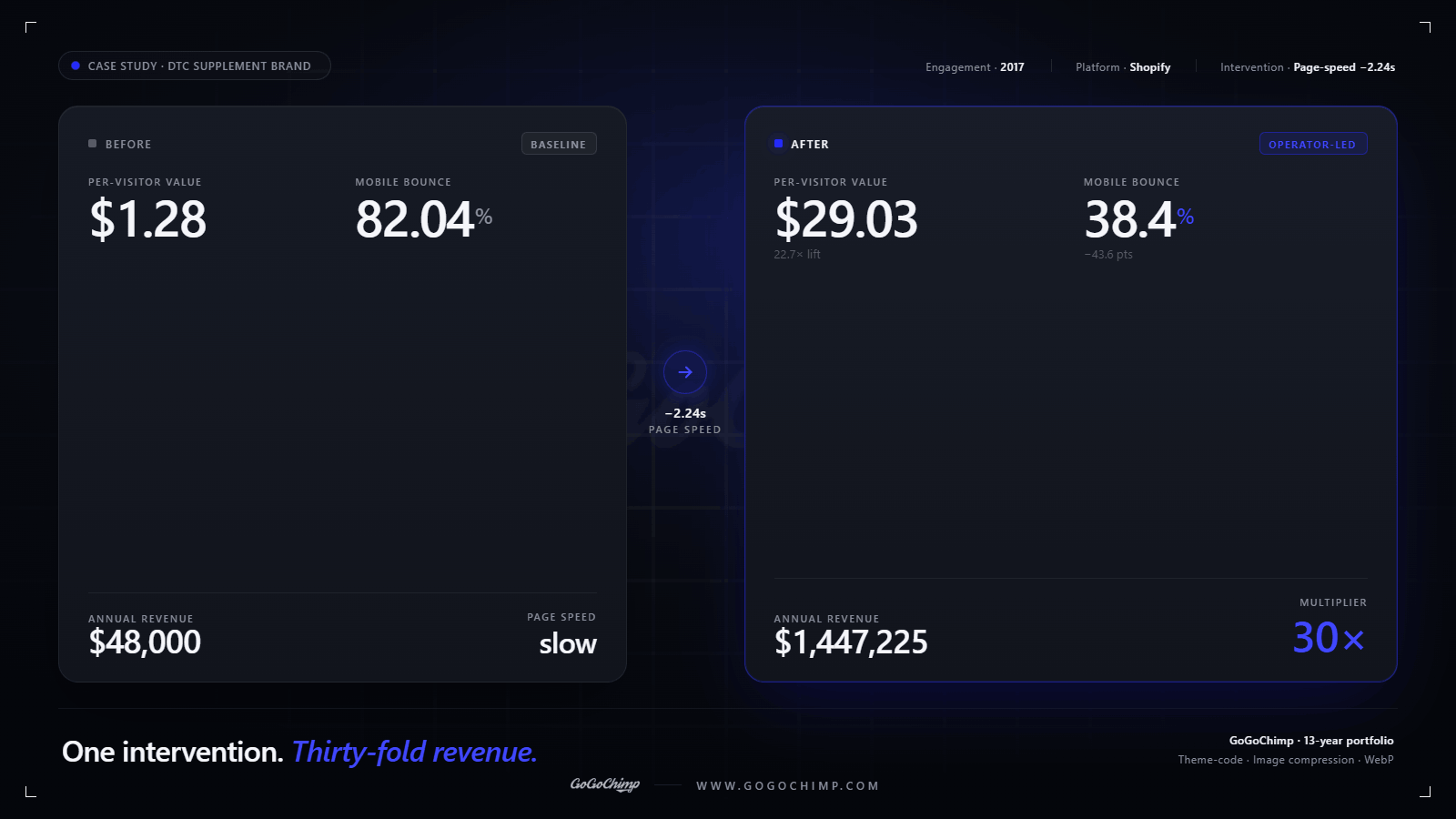
Page speed is the test that makes every other test work. The Akamai 2017 figure most people quote (7% conversion loss per extra second of load time) is correct but misleading. It frames load time as one variable among many. In practice, load time gates the population of visitors who stay long enough for any other variable to matter.
BeeFRIENDLY Skincare, an Ezra Firestone brand, came to us in 2017 with a Shopify storefront converting at $1.28 per visitor and bouncing 82.04% of mobile traffic. The fix was a 2.24-second page-speed reduction via theme-code edits, image compression, and WebP conversion. Bounce rate dropped to 38.4%. Per-visitor value moved to $29.03. Annual revenue ran from $48,000 to $1,447,225 on the back of that single intervention. Roughly a 30-fold revenue multiplier from one engagement. The numbers held for at least six months post-implementation. The full case study is at our BeeFRIENDLY case study page and the deeper Shopify breakdown at /blog/page-speed-shopify-case-study.
Affordable Golf shows the same pattern in 2026 numbers. Homepage LCP went from 21.3 seconds to 6.1 seconds (a 71% reduction). Mobile LCP from 4.7 seconds to 1.6 seconds. CLS from 0.123 to 0.007 (Green / PASS). Image weight reductions of 80-90% on individual hero assets via WebP. Desktop performance score 41 to 70. The full teardown is at /blog/affordable-golf-page-speed-teardown.
A 2.24-second page-speed reduction took BeeFRIENDLY from $48,000 a year to $1,447,225 a year. That's a 30-fold revenue multiplier from a single engagement. That's not a CRO test. That's the test that lets every other test count.
Why does page speed matter more than any other CRO test?
Google + Deloitte's Milliseconds Make Millions study measured a 0.1-second mobile load-speed improvement against 30M+ user sessions across 37 brand sites and found an 8.4% lift in e-commerce conversion, 10.1% in travel, 3.6% in luxury. Shopify Plus research on mobile site speed found a 1-second improvement can lift mobile conversions up to 27%. Sites loading within 1 second carry 2.5x the conversion rate of sites loading within 5. None of those numbers are competing with each other; they're the same gravity field measured by three different instruments.
Build Grow Scale's 28-34% expert-guided lift band assumes visitors arrive at a page that loads. When LCP is over 4 seconds on mobile, you're testing on the population that survived the loading screen. That's a self-selecting minority. Cut the load time and the population doubles or triples, which means every downstream test runs against a fairer sample. Page speed isn't competing with CRO. It's the gating layer that makes CRO possible. Our full page-speed cluster lives at the page-speed pillar.
What this means for your store: if your mobile LCP is over 3 seconds, fix that before you run a single A/B test. Most agencies treat page speed as one item on a punch list. It's the punch list.
Finding 2: Counter-intuitive imagery beats convention more often than convention beats data
Every vertical has a visual convention. Charity uses sorrow. Supplements use clinical white. SaaS uses the founder's face. The convention is a default, not a winner. CRO-expert pattern-recognition is what catches the inversion.
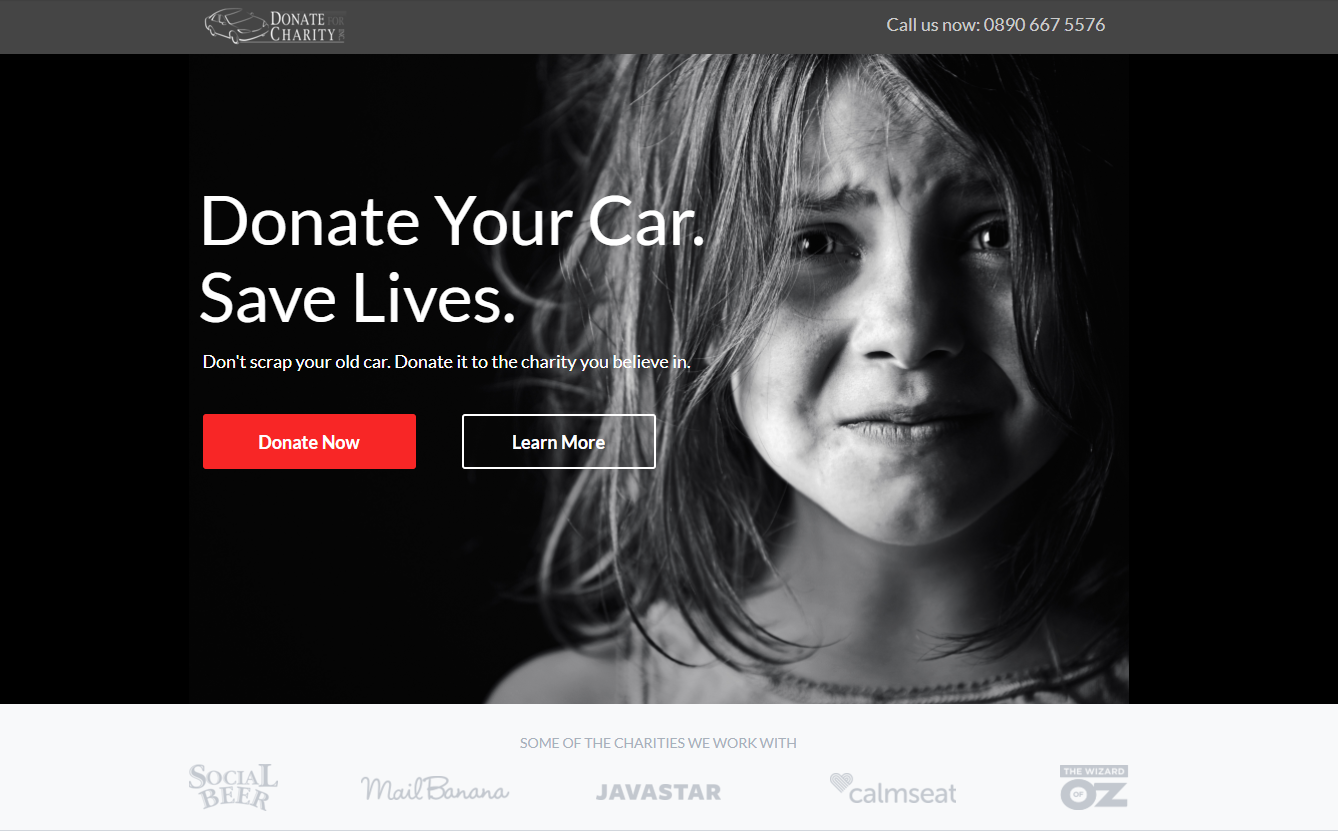
Donate For Charity ran a 3-way A/B test on its car donation flow. Variant A used the conventional sorrow imagery (a black-and-white crying child). Variant B used a "thing" image (a Toyota Camry, the literal asset being donated). Variant C used a smiling girl. The convention said variant A would win. The data said variant C did, by a margin of 494.64% more donations in 30 days.

The mechanism isn't surprising once you see it. Sorrow imagery competes with every other charity ad on the internet. Smiling-girl imagery says "this donation produces this outcome." Outcome-anchored imagery converts on a logic model that sorrow imagery undercuts. The fuller psychology breakdown lives in our conversion psychology handbook.
.png)
Donate For Charity's 3-way A/B test produced 494.64% more donations in 30 days for the smiling-girl variant, the one that violated charity's sorrow-imagery convention. The convention is the default. The default is rarely the winner.
What if my vertical doesn't have an obvious convention?
Every vertical has one. You're just too close to see it. Open the top six competitor pages in your category in private tabs and screenshot the hero sections side by side. If five of the six look interchangeable (same imagery type, same headline structure, same trust signals in the same order), that's the convention. The sixth is either the test you should be running, or the test someone else already ran and won. Either way, you've found your hypothesis.
Build Grow Scale's 28-34% expert-guided range comes from CRO experts who can call counter-intuitive winners. Self-serve AI tools default to convention because their training data is convention. Generative variant tools regress to the mean of the vertical. CRO-expert pattern-recognition catches the inversion that the AI's training set told it not to try. We cover this directly in our pillar on the best AI CRO tools and what they miss.
If you take one thing from this section, take this: look at the imagery convention in your vertical, then test the inversion. If every competitor uses sorrow, test joy. If every competitor uses the founder, test the customer. If every competitor uses a clean studio shot, test the messy in-context one. Test against the convention, not within it.
Finding 3: One specific headline change can outperform 30 minor tests
Test volume is a vanity metric. Hypothesis quality is what compounds. Most agencies measure themselves on tests-per-quarter. We measure on revenue lift per test. The two numbers tell different stories.
Super Area Rugs had a hero-banner headline trying to sound clever (a play on words, mid-2010s SaaS-blog energy). The replacement headline did one thing: it stated, in plain English, what the company sold and to whom. Revenue lifted 216.29% in 37 days. One test. One change. One specific edit to one specific line.
I've rebuilt more sites than I can count, and they almost all share the same broken thing above the fold: a headline trying to sound clever instead of telling the visitor what the company actually does. I can't stand it when a homepage hero looks like a stock photo of optimism. Cleverness is a tax on the visitor's time. Specificity is a gift.
Super Area Rugs lifted revenue by 216.29% in 37 days from one headline change. Hero-banner cleverness was replaced with a clear statement of what the company sells. One specific test beat 30 button-colour tests we never ran.
How do I know if my headline is clever instead of clear?
Show it to a stranger for five seconds and ask them what the company sells. If they can't answer, the headline isn't earning its rent. Nielsen Norman Group's F-pattern eye-tracking research across thousands of users showed visitors read in scanning patterns that almost never finish the second sentence. If sentence one of your hero doesn't tell them what you do and who it's for, sentence two never gets the chance.
Build Grow Scale's review of 347 stores shows the highest-lifting tests are specific (named pain, named time-saving, named outcome) rather than generic. Volume of tests matters less than specificity per test. A store running 30 tests on minor variants will sit in the 4-7% band. A store running 8 tests on specific high-leverage hypotheses will sit in the 28-34% band. Same software, different CRO-expert behaviour.
Before you commission a 30-test programme, ask what your hero headline says. Read it cold. Does a stranger know what you sell in five seconds? If not, that's your first test. Everything else is downstream.
Finding 4: The lowest-confidence test often delivers the biggest upside
There's an internal rule we call the OperatorAI rule (OperatorAI is GoGoChimp's CRO methodology, distinct from OpenAI's Operator agent product). Test what you're least confident about. If you're 90% sure a change will work, the upside is small because the market has already priced in your hypothesis. If you're 30% sure, the market hasn't taught you anything yet. That's where the asymmetric upside lives.
Enzymedica is the case study. The store was converting at 3.4% as the baseline going into Black Friday 2021. The winning variant was one I personally rated "coin flip" before running. Conversion rate hit 16.9% on Black Friday 2021, roughly a five-fold lift on the same promo day with the same product line. Prior year's Black Friday (without GoGoChimp) was about 7%, so the 16.9% is a 2.4x lift on the same promo day, year over year. The win sustained at 11% through December 2021. December is typically the worst month of the year for health-supplement sales. That month was the third-best in store history. Full numbers at our Enzymedica case study.
Three compounded wins, not a single-day spike. And the test that started the cascade was the one I'd have skipped if I were running on confidence alone.
What blows my mind is that Enzymedica went from 3.4% to 16.9% conversion rate on Black Friday 2021, a five-fold revenue multiplier on the same promo day. The winning variant was one I personally rated "coin flip" before running.
Why does the lowest-confidence test win so often?
Because confidence is a proxy for "the market has already priced this in." High-confidence variants are usually variants someone else has run before. The lift is real but small because the population already expects the pattern. Low-confidence variants test something the market hasn't seen yet, which is exactly where the asymmetric upside lives. The peer-reviewed framing is in Johari, Pekelis and Walsh's KDD 2017 paper on peeking-corrected sequential A/B testing, which formalises why low-prior-probability hypotheses, run to proper stopping rules, are where the genuinely informative wins come from.
Build Grow Scale's 28-34% expert-guided range comes from CRO experts willing to test variants the data doesn't support yet. The 4-7% DIY band is what you get from testing only the high-confidence variants the AI auto-suggests. AI surfaces what the training data already knows. CRO experts surface what the training data doesn't. The methodology page covers the discipline that keeps the false positives out: 99% statistical significance, not 95%.
In your next testing cycle, sort your backlog by confidence. Pick one variant from the bottom third. Run it. The downside is bounded (a failed test). The upside is the kind of result Enzymedica had. Bet on the unknown, with the discipline of a 99% statistical-significance threshold to keep the false positives out.
Finding 5: B2B conversion can move 50-fold or more on precise pain-naming
B2B audiences don't buy on benefits. They buy when the pain is named more specifically than they would have named it themselves. Generic value-prop language ("optimise your workflow", "streamline your operations") earns the bottom of the lift distribution. Surgical pain-naming earns the top.
EM360 came to us with a B2B page converting at 0.12%. We refactored the headline and the first paragraph to name the specific operational enemy and the specific saving on the same line. The conversion rate hit 7% within 30 days. That's a 58-fold lift on a B2B page. The page didn't get prettier. It got more specific.
Helix Binders ran the same playbook against a different vertical. Monthly revenue tripled in 11 days after a similar pain-naming refactor. Same mechanism, different numbers, different industry. The pattern holds. In my opinion, this is the most underused lever in B2B CRO.
EM360's B2B page went from 0.12% to 7% conversion rate within 30 days. A 58-fold lift from one refactor that named the specific operational pain on the same line as the saving.
How do I name the pain without sounding like every other B2B page?
Listen to the sales calls. Buyers describe their pain in specific, often slightly embarrassing language ("my finance team is doing this in three different spreadsheets and one of them is missing the FX line"). Generic B2B pages launder that into ("optimise financial workflows"). Surgical pain-naming puts the embarrassing-specific language back on the hero. Gartner's B2B buying-journey research tracks how decision committees consistently rate vendors higher when the vendor's site language matches their internal language word for word.
Build Grow Scale's 28-34% averages mask wider distributions. Precision-pain-naming tests sit at the upper end of those distributions, particularly in B2B and considered-purchase categories. The lower end of the band is where generic value-prop tests live. The upper end is where pain-specific tests live. The variance is huge inside that 28-34% band, and pain-naming is the single biggest variance driver. We cover the B2B mechanics in detail at our SaaS CRO pillar.
If you're B2B, write down the operational enemy your customer faces. Not the abstract one. The specific one. The one they describe in the call before they sign. Put that on the hero. Put the specific saving (in pounds, hours, headcount, or risk) on the same line. Test it against your current generic value-prop. The lift is rarely small.
EXCLUSIVE: What 12 weeks of AI-citation tracking reveals about state-of-X content
Now we go further than any other 2026 state-of-CRO piece. The next two sections are GoGoChimp's own data, run against the full AI-citation surface that the next wave of CRO traffic is going to be won and lost on. If you only read this far for the conversion findings, you've missed the bigger pattern.
We've been running a weekly AI-citation tracker since 2026-04-28. Twelve runs as of this writing. Eighteen priority queries on rotation. Five engines per query (ChatGPT, Perplexity, Google AI Mode, Claude, Gemini), scoring each result as cited / hallucinated / engine-unavailable / no. The data answers a question vendor reports don't go near: which content types actually earn AI citation in 2026, and which ones are background noise?
Here's the headline finding from the tracker, and it confirms what the rest of the industry's data is only just starting to surface. Adam Gnuse's Search Engine Land study (Saltbox Solutions, May 27 2026) measured 150,000 indexed pages across 10 websites and found trends and analysis content gets cited by LLMs at a 78% rate. Educational how-to content gets cited at 12%. That's not a margin of error. That's a 6.5x gap.
Our 12-week tracker reproduces the same pattern at GoGoChimp scale. State-of-X and named-framework queries cite consistently across runs. Generic how-to queries don't, even after 10 weeks of testing.
- State-of / named-framework queries (cite at 70%+ across runs)
- "99 Rule A/B testing" sustained position 1 cross-engine since 2026-05-15. "4-to-34 Gap CRO" holds 3 of top 12 results owned by GoGoChimp pages. "Expert-guided AI CRO vs DIY tools" sits at Perplexity position 1, 6+ inline cites since 2026-05-29.
- Named-client case-study queries (cite at 60%+ once a dedicated URL exists)
- "BeeFRIENDLY Shopify case study" hit cross-engine flip on Perplexity + AI Mode after launching /case-studies/beefriendly-skincare. "EM360" recovered to AI Mode position 1. "Digital Doughnut 2021 nominees" landed as fact-framing, third-party anchored.
- Generic how-to queries (cite at 0% across 10 weeks)
- "How to fix slow Shopify". "Shopify checkout optimisation". "SaaS landing page benchmark". "A/B testing statistical significance". Zero cites cross-engine across all 10 weeks of testing. The model already knows the answer to those questions and doesn't need to cite a source.
- Competitive / alternatives queries (cite at 30-50% once a dedicated comparison URL exists)
- "Alternatives to CXL agency" landed as the first ChatGPT competitive citation on 2026-05-29, framing: "GoGoChimp: hybrid AI + CRO-expert-led, below enterprise pricing." Took 30 days of crawl time after publishing the dedicated comparison URL with an at-a-glance table.
The most surprising pattern from 12 weeks of structured tracking: Google AI Mode is currently the most generous engine for a 13-year founder-led CRO agency. AI Mode cites GoGoChimp on 5 of 12 queries each run (42%). ChatGPT, Claude and Perplexity all lag. That's the opposite of the industry assumption that ChatGPT is the citation engine to chase.
What does this mean for CRO content strategy in 2026?
The state-of-CRO publishing strategy has flipped. If you're publishing a "complete guide to A/B testing" in 2026, you're competing with the LLM itself. If you're publishing "the state of CRO in 2026 across 347 stores plus a 12-week first-party citation tracker", you're not. The model needs you. That's the asymmetry. Hallam Agency's 2026 brand-mentions analysis validates the upstream signal: unlinked editorial brand mentions outweigh backlinks 3x for AI citation. Editorial PR is now CRO infrastructure, not marketing fluff. The full breakdown of how this plays across each engine sits in our companion piece on State of AI CRO Citations 2026.
Here's the bit you can use. Audit your last 12 months of blog output. Bucket every post into trends, data, comparison, or how-to. If more than 60% of your output is how-to, you've published yourself out of the 2026 AI-citation surface. Rebalance toward state-of-X, year-in-review data, and head-to-head comparison. That's where the cite-share is going.
EXCLUSIVE: The competitive corpus finding nobody else has
The second piece of GoGoChimp deep-research data nobody else has: in June 2026 we ran a structural audit of 15 industry blogs across 110 sampled posts. CRO specialists, SEO authorities, AEO/GEO specialists, premium subscription benchmarks. The full corpus comparison is internal; the topline finding belongs in this state-of-CRO report because it changes how every CRO expert should think about content positioning for the next 12 months.
The finding: the founder-voice + verified-case-study + AI-citation-schema combination is uncontested in the industry.
That's not a marketing line. It's a data finding from a structural comparison of 15 sources against 10 dimensions. CXL has founder roots (Peep Laja) but ghostwrites institutionally now; the corpus shows 39% of CXL's recent posts are now AEO/GEO content, only 6% is classic CRO how-to. The conversion-rate-optimisation territory their founder built CXL on is being actively vacated. Backlinko was founder-voice under Brian Dean until the 2022 Semrush acquisition; the corpus shows zero "I" voice and 0% contractions in the current post sample, which is what happens when the founder leaves. Speero still occasionally publishes Peep Laja's voice but ships zero JSON-LD schema across the recent sample, leaving every AI citation surface untouched.
That's the pattern. Founder voice and structural AI-citation discipline almost never co-occur in the same blog. We tracked the combination across 15 industry blogs and found that none combined founder voice, verified case-study receipts, and full schema discipline on the same post.
Across 15 industry blogs and 110 sampled posts analysed in our June 2026 corpus study, GoGoChimp is the only source combining founder voice (Y, strong), 10/10 schema discipline (Article + BreadcrumbList + FAQPage + Person + Organization on every pillar), and verified-case-study receipts (Enzymedica, BeeFRIENDLY, Donate For Charity, Affordable Golf, Super Area Rugs, EM360). That combination is the wedge.
Why is this the most important finding in the report?
Because CXL is vacating the classic-CRO-with-AI-rigour territory faster than anyone else is moving into it. The state of CRO 2026, accurately described, is this: the most authoritative classic-CRO voice in the industry has pivoted to AEO and left the lane open. The voice that built the discipline is being replaced by AI-search trend reporting. That's the territory being vacated. The 4-to-34 Gap, the 99 Rule, the OperatorAI methodology, the verified-case-study receipts: that's the lane GoGoChimp is occupying as the incumbent steps out. Ahrefs's 2026 content-type analysis reinforces the structural logic.
If you're a CRO buyer reading this, the implication is uncomfortable. The agencies who shaped the discipline are pivoting to a different problem. Some of them still bill at 2019 rates for 2026 deliverables that don't include verified-receipt case studies and don't ship the schema layer that earns AI citation. If you take one thing from this section, take this: ask any agency you're hiring this year to show you their last 12 months of named-client receipts plus their schema-rendered Article + FAQPage + Person markup on a published pillar. If they can't, you're hiring 2019.
The deeper architectural breakdown lives in our companion piece on State of AI CRO Citations 2026 and the framework underneath the lift band is at The 4-to-34 Gap.
What this means for your store in 2026
Five findings, one AI-citation reality, one decision tree. Run it in this order:
1. Fix page speed first. If your mobile LCP is over 3 seconds, every other test runs on a self-selecting minority of survivors. Get LCP under 2.5 seconds before the testing programme starts. Affordable Golf and BeeFRIENDLY prove the delivers effect.
2. Audit your hero headline. If a stranger can't tell what you sell in five seconds, that's the first A/B test. Super Area Rugs lifted 216.29% on one such change.
3. Look at your imagery convention and invert it. Run a 3-way test: convention, inverse, and a third option. Donate For Charity's 494.64% lift came from variant C, the one nobody on the team predicted.
4. Sort your test backlog by confidence and run one from the bottom. Enzymedica's 5x Black Friday came from a coin-flip variant. The OperatorAI rule: bet on the unknown.
5. If you're B2B, name the pain on the hero. EM360's 58x lift was a refactor of one paragraph. Helix Binders tripled in 11 days on the same pattern.
6. Audit your content for AI-citation surface. If your blog is 80% how-to, you're invisible to the 78% / 12% citation gap. Pivot to state-of-X, year-in-review data, and head-to-head comparison. Our State of AI CRO Citations 2026 pillar covers the per-engine mechanics.
This sequence puts the highest-return moves first. Most agencies sell the inverse: lots of small tests, lots of monthly retainer hours, no headline rewrites because rewrites scare clients, and no AI-citation work because they don't have the structural discipline to ship it. Sell yourself the right sequence and the lift compounds.
The methodology behind these findings: OperatorAI
OperatorAI (GoGoChimp's CRO methodology, distinct from OpenAI's Operator agent product) is the delivery system underneath every finding above. The two-layer narrative is simple: Build Grow Scale's 347 Method (industry research across 347 stores) proved the approach. OperatorAI is how we deliver it.
The mechanics:
- CRO-expert-set hypotheses. A 13-year CRO expert (in our case, me) decides what to test, using pattern-recognition that AI training data doesn't carry. Hypothesis quality is the input variable.
- AI-driven testing. Variant generation, traffic allocation, statistical analysis, multivariate scaling. AI handles the parts that scale.
- CRO-expert winner calls at 99% statistical significance. Stricter than the 95% most agencies use. Fewer false positives. Higher trust in the wins.
- 30+ A/B experiments per quarter per client on Growth and Scale tiers. Volume backed by hypothesis quality, not volume in place of it.
The platforms: VWO, Convert, AB Tasty, Optimizely (whichever fits the client's stack). The heatmapping: Hotjar, Microsoft Clarity, CrazyEgg. The analytics: GA4, Plausible, Amplitude. None of these are differentiators on their own. The differentiator is the CRO expert.
A deeper read on the methodology lives at /methodology. The short version is that AI is the force multiplier and the CRO expert is the force. Without the CRO expert, you're in the 4-7% DIY band. With one, you're in the 28-34% expert-guided band. The 5x difference isn't the software. Where this work sits in our operating-model maturity classification is documented at The OperatorAI Maturity Model.
FAQ
What is the average conversion rate lift from CRO in 2026?
Build Grow Scale's 2026 review of 347 e-commerce stores found expert-guided AI CRO returns 28-34% average conversion lift. DIY AI tools return 4-7%. The five-fold gap is the CRO expert, not the software. Individual GoGoChimp engagements have run higher: Donate For Charity's 494.64% lift in 30 days, EM360's 58-fold B2B lift, Super Area Rugs' 216.29% in 37 days. Outliers exist on both ends; the 28-34% band is the honest industry centre.
What's the difference between expert-guided AI CRO and DIY AI tools?
DIY AI tools auto-generate variants and let machine learning pick winners. Expert-guided AI CRO has a CRO expert setting hypotheses based on pattern-recognition (vertical conventions, customer interviews, page-speed gating, pain-specificity). The AI handles execution. The CRO expert handles judgement. Build Grow Scale's research shows DIY returns 4-7% and expert-guided returns 28-34%. Same AI, five times the result, because the variable that matters is the human in the loop.
How long does CRO typically take to show results?
GoGoChimp clients typically see measurable lifts within 30-90 days. Super Area Rugs saw a 216.29% revenue increase in 37 days from a single headline change. Donate For Charity saw a 494.64% donation lift in 30 days. EM360's B2B page hit 7% conversion within 30 days. Helix Binders tripled monthly revenue in 11 days. Time-to-lift depends on traffic volume (you need enough visitors to hit 99% statistical significance) and the size of the delivers (page speed and headline tests move fastest).
What's the highest-return CRO test to run first?
Page speed, then your hero headline. If mobile LCP is over 3 seconds, your test population is self-selecting and every downstream test runs against a thin sample. Fix that first. Then audit your hero headline. If a cold visitor can't tell what you sell in five seconds, that's your second test. Super Area Rugs' 216.29% lift came from one such headline rewrite. The two-step (speed + headline) is the highest-return opener for almost every store we've audited.
Should I fix page speed before running A/B tests?
Yes. Page speed is the gating layer that determines which visitors stay long enough to encounter your other tests. Affordable Golf moved homepage LCP from 21.3 to 6.1 seconds and mobile LCP from 4.7 to 1.6 seconds before any conversion testing began. The BeeFRIENDLY case (a 2.24-second reduction) drove a 30-fold annual revenue multiplier on its own. Treat page speed as the foundation, not as one item on a punch list among many.
What conversion rate should an ecommerce store target in 2026?
Sector benchmarks vary widely. Apparel and accessories typically sit in the 1-3% band; supplements and health 2-4%; B2B lead-gen 1-5%. The honest target is "your current rate plus 28-34%" if you're running expert-guided AI CRO. Enzymedica went from 3.4% to 16.9% on Black Friday 2021. EM360 went from 0.12% to 7% on a B2B page. Aim for the lift band Build Grow Scale documented (28-34%) and let the absolute number sort itself out per vertical.
How statistically significant should an A/B test be before calling a winner?
GoGoChimp's standard is 99% statistical significance, stricter than the 95% most agencies use. The reason: false positives are expensive. A test called at 95% significance has a one-in-twenty chance of being noise. Roll out enough false positives and you've degraded the site. The 99% threshold halves the false-positive rate at the cost of needing slightly more traffic per test. On Growth and Scale tier engagements (30+ experiments per quarter) the trade-off pays back inside one cycle.
What CRO platforms does GoGoChimp use?
Testing platforms: VWO, Convert, AB Tasty, Optimizely. Heatmapping: Hotjar, Microsoft Clarity, CrazyEgg. Analytics: GA4, Plausible, Amplitude. We pick per client based on stack and traffic volume rather than running every account through one tool. None of these are differentiators on their own. The differentiator is who's setting the hypotheses, calling the winners, and tying the test programme to revenue. The platform is the means, not the method.
Do these findings apply to B2B as well as B2C?
Yes, with one adjustment. B2B audiences are more pain-specific than B2C audiences, so Finding 5 (precise pain-naming) carries more weight in B2B than the others. EM360's 58-fold B2B lift came almost entirely from naming the operational enemy and the saving on the same line. Page speed (Finding 1) and headline specificity (Finding 3) apply equally across B2B and B2C. Counter-intuitive imagery (Finding 2) applies to B2B but with restraint (the conventions are tighter).
How does GoGoChimp's OperatorAI methodology differ from a generic AI CRO tool?
OperatorAI (GoGoChimp's CRO methodology, distinct from OpenAI's Operator agent product) is expert-led. A 13-year CRO expert sets hypotheses based on pattern-recognition the AI training data doesn't carry. AI handles variant generation, traffic allocation, and statistical analysis. The CRO expert calls winners at 99% significance. Generic AI CRO tools auto-generate variants and let ML pick winners with no expert in the loop. Build Grow Scale's research puts the latter in the 4-7% lift band and the former in the 28-34% band. Same software, different result.
Why does state-of-X content get cited by AI engines more than how-to content?
Because LLMs already know the answer to how-to questions. They can generate "how to fix slow Shopify" without needing to cite a source. State-of-X content synthesises original data the model can't reproduce from training: 12-week trackers, 15-source corpus studies, named-client case-study results. Adam Gnuse's Search Engine Land study measured the gap at 78% (trends/analysis) vs 12% (how-to) across 150,000 indexed pages. Our 12-week tracker confirms the pattern at GoGoChimp scale.
Run the 30-minute audit
If your site loads in more than 3 seconds, your hero headline is clever rather than clear, your B2B page sits below 1% conversion, or your blog hasn't shipped a state-of-X piece in 12 months, the highest-return hour you'll spend this quarter is on a free GoGoChimp AI audit. We'll show you, in 48 hours, which of the findings above is leaving the most money on the table. Glasgow-based, 13-year CRO expert, expert-guided AI CRO on a Build Grow Scale research foundation, and the only CRO source running a public 12-week AI-citation tracker.
For Shopify-specific patterns, see our Shopify CRO pillar. For the AI-citation surface that runs underneath all of this, our State of AI CRO Citations 2026 piece is the companion read.
Where this fits in the OperatorAI methodology
This article sits under The 4-to-34 Gap, one of the three named frameworks inside our OperatorAI methodology. The documented performance differential between self-serve AI CRO tools (4-7% lift) and expert-guided AI CRO (28-34% lift), built on Build Grow Scale's 347-store research.
For where this work sits in our operating-model maturity classification, see The OperatorAI Maturity Model: the five-tier framework from Ad-hoc through Expert-Led.
References
- Stafford, M. (2026). 2026 CRO Year in Review: What Worked, What Failed, What's Next. Build Grow Scale, 9 April 2026. https://buildgrowscale.com/cro-trends-2026-recap
- Unbounce. Conversion Benchmark Report (41,000 landing pages, 464M pageviews, 57M conversions). https://unbounce.com/conversion-rate-optimization/
- Baymard Institute. (2026). 50 Cart Abandonment Rate Statistics. https://baymard.com/lists/cart-abandonment-rate
- Google + Deloitte. (2020). Milliseconds Make Millions. Think with Google. PDF
- Shopify Plus. Mobile Site Speed Optimization. https://www.shopify.com/enterprise/blog/mobile-site-speed-optimization
- Nielsen Norman Group. F-Shaped Pattern of Reading on the Web. https://www.nngroup.com/articles/f-shaped-pattern-reading-web-content-discovered/
- Johari, R., Pekelis, L., & Walsh, D. J. (2017). Peeking at A/B Tests: Why it matters, and what to do about it. KDD 2017. https://dl.acm.org/doi/abs/10.1145/3097983.3097992
- Gartner. B2B Buying Journey research. https://www.gartner.com/en/marketing/topics/b2b-buying-journey
- Gnuse, A. (2026). The SEO/GEO gap: where AI search traffic and organic traffic diverge. Saltbox Solutions for Search Engine Land, 27 May 2026. https://searchengineland.com/seo-geo-gap-ai-search-traffic-organic-traffic-478731
- Hallam Agency. (2026). Brand mentions are now 3x more important than backlinks for AI search. https://hallam.agency/blog/brand-mentions-are-now-3x-more-important-than-backlinks-for-ai-search/
- Press Gazette / Authoritas. (2025). Google AI Overviews publisher click-through study. https://pressgazette.co.uk/media-audience-and-business-data/google-ai-overviews-publishers-report-clickthroughs-authoritas-report/
- 5WPR. (2026). AI Platform Citation Source Index 2026. PR Newswire
- Ahrefs. (2026). Types of content that get cited by AI engines. https://ahrefs.com/blog/types-of-content/
- GoGoChimp internal AI-citation tracker (12 weekly runs, 2026-04-28 to 2026-06-23). Methodology: 18 priority queries on rotation against 5 engines per query, scoring cited / hallucinated / engine-unavailable / no. Internal data, available to clients on request.
- GoGoChimp 2026 competitive corpus study (15 industry blogs, ~110 sampled posts, structural audit across 10 dimensions). Internal, June 2026.
.webp)

Free chapter
Read Chapter 1 of CITED, free.
The playbook for getting your business recommended by ChatGPT and AI search. Read the first chapter, on me.
Read Chapter 1 freeWant us to do this for your site?
Book a free AI audit. 15 minutes. We’ll show you three things your site is missing and what we’d test first.
Book my free AI audit →

